
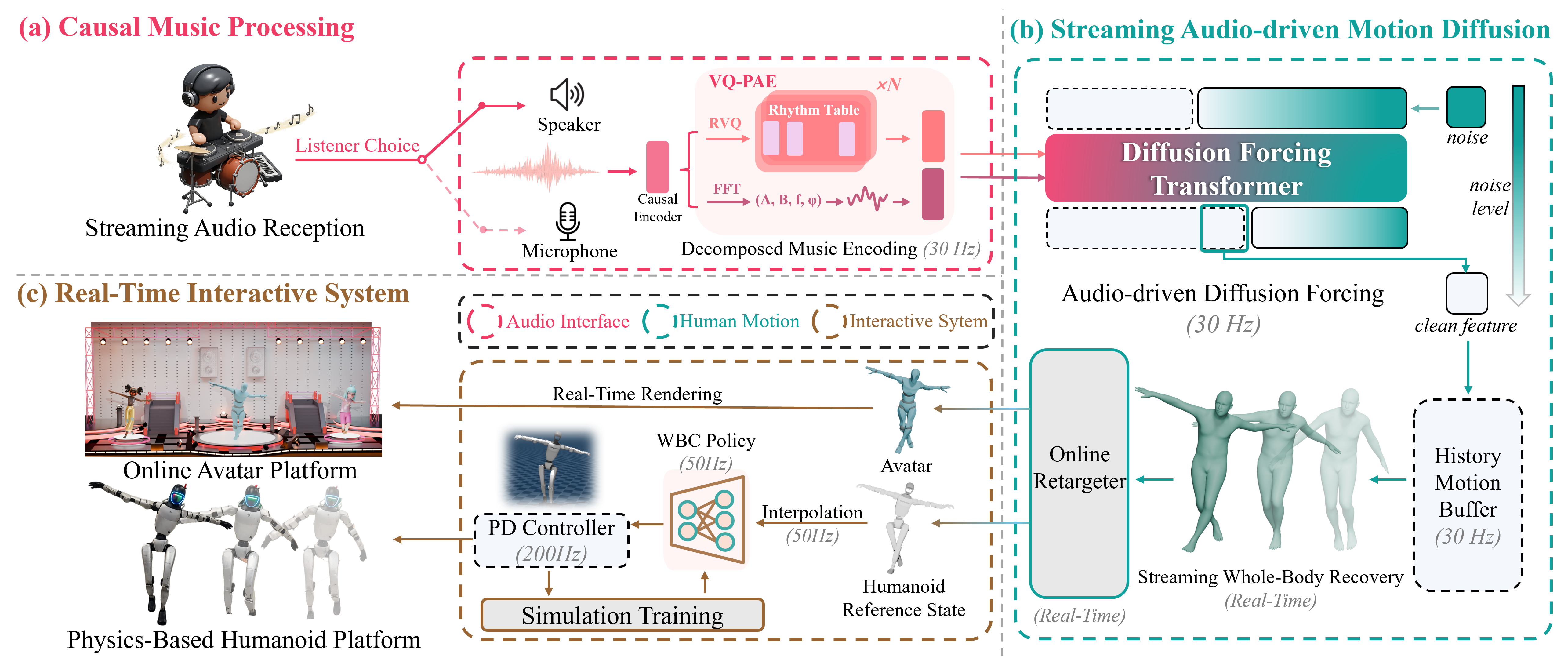
We study real-time audio-responsive character control as a deployment-faithful problem: strictly causal, bounded-latency streaming that must generate coherent full-body motion at interactive frame rates while the audio condition can change abruptly (tempo shifts, drops, or user edits). Prior music-to-motion systems are largely optimized for offline generation with global context, and degrade in streaming rollouts where conditioning history becomes stale or unreliable. We introduce DiscoForcing, a streaming audio-driven diffusion framework that combines a causal music encoder that captures rhythmic structure and phase dynamics with a diffusion-forcing sequence model trained under heterogeneous noise levels across the temporal horizon. Building on this, we design a hybrid temporal schedule and a history-guided streaming sampler to explicitly trade off responsiveness against long-horizon consistency under non-stationary audio. Implemented in an end-to-end real-time interactive system with online avatar playback and humanoid deployment workflows, DiscoForcing delivers more stable long-horizon rollouts and sharper audio-motion alignment than prior baselines under matched causality and latency constraints while maintaining real-time throughput.

@inproceedings{ji2026discoforcing,
title={DiscoForcing: A Unified Framework for Real-Time Audio-Driven Character Control with Diffusion Forcing},
author={Ji, Kaiyang and Qian, Bingsheng and Wu, Binghuan and Chen, Kangyi and Shi, Ye and Wang, Jingya},
booktitle={Forty-third International Conference on Machine Learning},
year={2026}
}